I recently spoke at Devoxx Belgium about Camel Quarkus (you can find the recording here: https://youtu.be/FBWgbhp8FG8) and for this talk I wanted to demonstrate just how easy it is to integrate different components using Camel. I also wanted some interaction with the audience and make the session a little more fun by having them participate in the demo.
My initial idea was a voting app where the audience could vote for their favorite IDE by using Twitter. It seemed like a neat idea, I could use the Twitter component of Apache Camel which I had already demo’d during a talk I did for the Openshift Coffee Hour (https://youtu.be/aaEV19c6GhQ), but ultimately I decided against it because I really wanted more than just a handful of votes (if that). Since my talk was also about using Camel Quarkus in a Serverless way I needed a LOT of votes from the audience :P.
What I came up with was to build a small web app where the audience could vote through the UI which would send a REST Get request to an API that I would expose using Camel; and then update a database that I could poll to show the results live on the big screen. I didn’t want the API requests to immediately update the database, but instead stream them to a Kafka topic first and then handle the requests and update the database under a controlled load. That would allow me to also demonstrate how easy it is to integrate Camel with Kafka. It’s basically one line of code:
to("kafka:{{kafka.topic.name}}")
Easy right?
I still wanted to show the Twitter component as well as an additional feature, and finally, just in case there weren’t going to be too many votes, I prepared another rest endpoint that I could call with jmeter to ‘cheat’ the result so I could show the audience how the system would scale pods out rapidly under load. Using Quarkus and Knative that’s super easy to do since Quarkus starts up super fast, and Knative scales out rapidly based on requests.
Architecture
The final architecture looks a little bit like this (forgive my crappy architecture design skills)
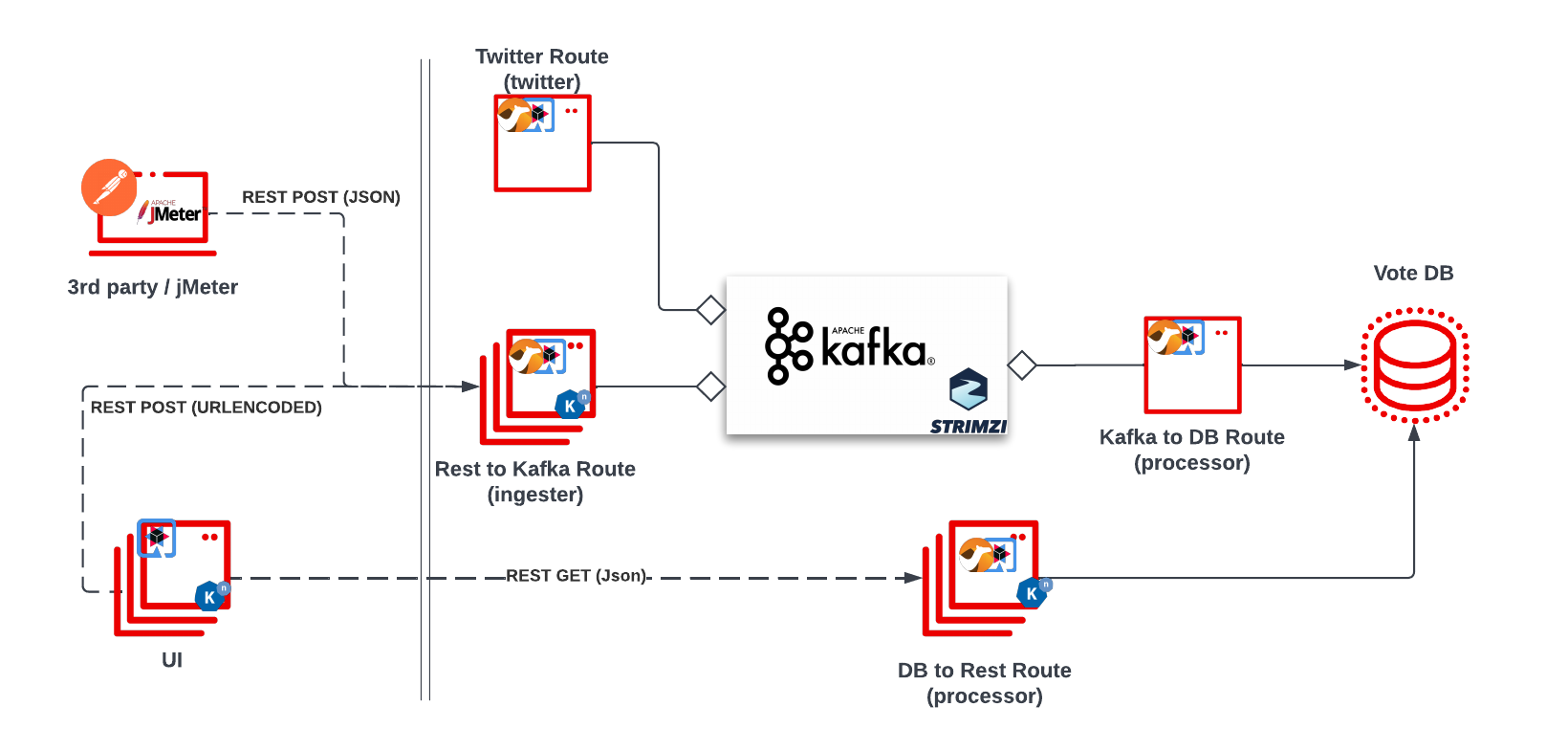
The UI application features a, well, UI, that shows the results of a poll and a form to vote for your favorite Java stack. When you vote, a REST POST event gets sent to the ‘ingester’ app, which will translate the result and add it to a Kafka topic.
The 3rd application (processor) consumes the Kafka messages at its own pace and updates the database accordingly. (eg. if someone voted ‘Vim’, the counter for vim would be incremented by 1) The ‘retriever’ application (currently embedded in the processor app) has a REST GET endpoint to get the results from the DB.
Anatomy
So ultimately the application is composed of the following components:
UI
The ui application displays a list of java stacks/frameworks that you can vote for by clicking the respective button next to it. This action calls the ingester app. The page also displays a bar chart of the results so far. The app is built with Quarkus Qute templating and some crappy javascript/jquery code :P
Ingester
The ingester Camel Quarkus application receives requests from the user (via HTTP) and forwards the requests to the Kafka broker. The main component of the application:
- RestToCamelRoute : Camel route that receives a rest call and forwards it on to a Kafka broker
Processor
The processor Camel Quarkus application receives the vote requests from Kafka, processes them, and writes results into the votesdb Postgres DB table. As of right now it also returns the results through a /getresults endpoint. The application has the following Camel Routes:
- processor/VotesRoute consumes messages from a kafka topic (in json format), extracts the value of ‘shortname’ and increments the counter of the java stack that matches with this shortname.
- RestRoute returns data from the votes table in json format
Twitter
The twitter Camel Quarkus application polls twitter for matches to my handle (@kevindubois) and scans for matches to the various IDEs I’m using.
- TwitterRoute polls twitter, and forwards any matches to the same Kafka topic messages
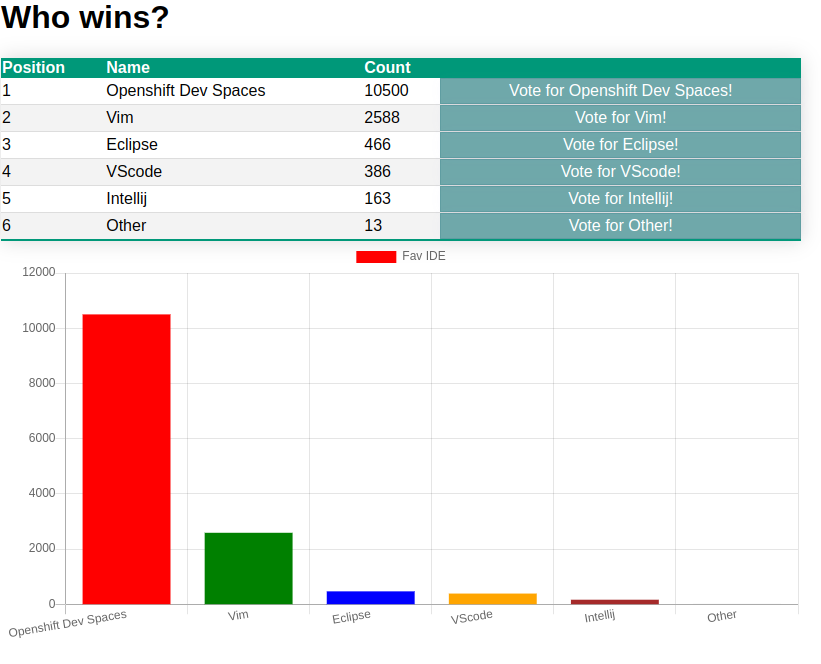
And this is basically the UI of the voting app:
You can find the source code in my github: https://github.com/kdubois/CamelQuarkusVoter